


📌 ChatGPT와 뉴스 기사 제목 크롤링 하기(Python 웹 스크래핑)

🗂 목차
- 🔹 웹 크롤링이란?
- 🔹 개발 환경 설정
- 🔹 Step-by-Step 코딩
- 🔹 전체 코드
- 🔹 실행 방법 & 결과
- 🔹 초보자 FAQ
1. 📰 웹 크롤링이란?
웹 크롤링(Web Crawling)은 특정 웹사이트의 정보를 자동으로 가져오는 기술입니다.
뉴스 기사를 직접 검색하지 않고, Python을 사용해 최신 뉴스를 자동으로 가져올 수 있어요!
🔹 실생활에서 활용 예시
- ✅ 특정 키워드가 포함된 뉴스 자동 수집
- ✅ 관심 있는 뉴스 제목만 모아서 한눈에 확인
- ✅ 뉴스 데이터를 엑셀 파일로 저장
2. ⚙️ 개발 환경 설정
Python과 필요한 라이브러리를 설치해야 해요.
📌 필요한 라이브러리 설치
pip install requests beautifulsoup4
→ 전에 한 번 설치 한적있으시죠? 날씨 불러오기와 같아요 ~
3. 🛠 Step-by-Step 코딩
1️⃣ 라이브러리 불러오기
import requests
from bs4 import BeautifulSoup
→ 날씨 불러오기를 따라하셨던 분들은 익숙하실거에요.
2️⃣ 뉴스 웹사이트에서 데이터 가져오기
url = "https://news.naver.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
→ 위 코드를 실행하면 아무런 결과가 표시되지 않아요. 그래서 아래처럼 한 줄 넣어봅니다.
→ 그리고 실행을 꾸욱~ 누르면 아래처럼 뭐가 막 출력되는걸 확인할 수 있어요.
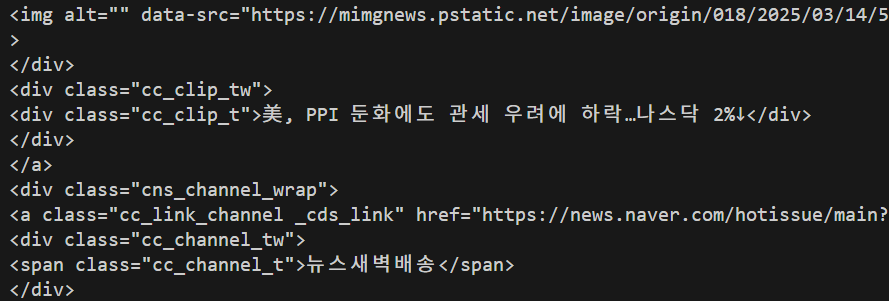
3️⃣ 뉴스 제목 크롤링
titles = soup.find_all("a", class_="news_tit") # 기사 제목 태그 선택
for title in titles:
print(title.text)
→ 제목을 잘 찾아올까요? 코드 입력하면서 출력결과를 상상해요.
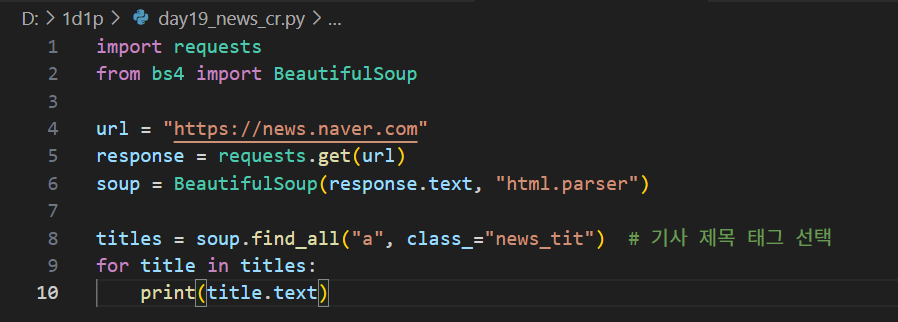
→ 결과는요? 안나오네요...
전에 날씨 불러오기와 같이 정확한 class명을 몰라서 그럴거라 추측해보고 코드를 확인해봐요.
[전체코드 수정]
→ class 중복도 많고 복잡해서 url 주소를 변경하고 chatGPT에게 html구조를 파악시키고 코드를 수정했어요. 😥
아래 전체 코드는 테스트 후 수정완료했습니다. 위에 코드에서 변경이 있어요!
4. 📜 전체 코드
import requests
from bs4 import BeautifulSoup
# 네이버 뉴스 URL
url = "https://news.naver.com/main/ranking/popularDay.naver"
headers = {"User-Agent": "Mozilla/5.0"}
# 페이지 요청
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
# 최신 뉴스 제목 태그 확인
titles = soup.select("div.rankingnews_box a") # 새로운 클래스 선택
# 결과 출력
for title in titles[:10]: # 상위 10개 뉴스만 출력
print(title.text.strip())
→ 실행결과에요~ 복잡해 보이는 코드를 보는건 아직 익숙치 않지만 재밌네요. 😉

5. 🚀 실행 방법 & 결과
- Python 파일을 실행하면 뉴스 기사 제목이 출력됩니다.
- 출력된 제목을 활용해 원하는 뉴스를 빠르게 찾을 수 있어요.
6. ❓ 초보자 FAQ
Q1. 크롤링이 안 돼요!
→ 웹사이트 구조가 바뀌었을 가능성이 있어요. find_all()의 태그를 다시 확인해보세요.
Q2. 특정 키워드가 포함된 뉴스만 보고 싶어요!
→ if "파이썬" in title.text: 같은 조건을 추가하면 원하는 뉴스만 출력할 수 있어요.
Q3. 뉴스 제목을 파일로 저장할 수 있나요?
→ with open("news.txt", "w", encoding="utf-8")을 사용하면 텍스트 파일로 저장할 수 있어요.
🎯 맺음말 & 발전 과제
오늘은 뉴스 기사 제목을 자동으로 크롤링하는 프로그램을 만들었어요!
역시나 날씨 불러오기와 같이 홈페이지 구조를 알아야 원하는 기사를 가져올 수 있네요.
💡 발전 과제
- ⚠ 뉴스 제목을 CSV 파일로 저장
- ⚠ 특정 키워드가 포함된 뉴스만 필터링
- ⚠ 여러 뉴스 사이트에서 제목 크롤링